오늘은 패킷 분석과 조금은 다른 이야기를 꺼내볼까 한다. 머 그렇다고 패킷 분석과는
동떨어진 내용은 아니다. 분석을 하다보면 필요한 내용이기 때문이다. 앞으로 계속
여러가지 내용을 소개하는데 있어, '바이트 오더(Byte Order)' 를 설명할 필요가 있을거 같아
잠깐 짚고 넘어가볼까 한다.
바이트오더 하면 떠오르는게 리틀 엔디안(Little Endian) 과 빅 엔디안(Big Endian) 이다.
프로그램이나 리버싱 과정에서 헷갈리기도 하는 부분이다.
우선 리틀 엔디안은 주로 인텔(Intel)프로세스 계열에서 사용하는 바이트 오더 이다.
메모리 시작 주소가 하위 바이트부터 기록된다는 것이고 그 반대로 빅 엔디안은
메모리 시작 주소에 상위 바이트부터 기록된다. 주로 UNIX 시스템인 RISC 프로세서
계열에서 사용하는 바이트 오더이다. 이렇게 메모리에 저장하는 방식이 차이가 있다보니
가끔 혼돈 스럽기도 하다. 다음 도표는 메모리기 기록되는 것을 쉽게 이해할 수 있도록 기술되어 있다.

[도표] 레지스터와 메모리 위치 매핑 관계 , 출처 : 위키피디아(www.wikipedia.org)
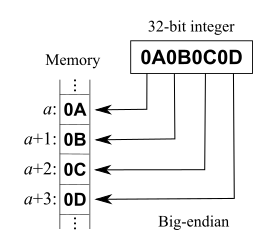
우리가 패킷분석때 많이 보게되는 네트워크 프로토콜은 기본적으로 빅 엔디안 표현이다.
빅 엔디안을 표현하면 아래와 같다.
| increasing addresses → | |||||
| 0Ah | 0Bh | 0Ch | 0Dh | ||
[출처] 위키피디아
0x0A 는 메모리 하위 주소에 위치하게 되고 차례로 0x0B , 0x0C, 0x0D 가 온다.
읽는 순서는 왼쪽 -> 오른쪽 순서로 읽으면 되므로 사람이 보기에는 가장 편한 방식이다.
다음 리틀 엔디안은
| increasing addresses → | |||||
| 0Dh | 0Ch | 0Bh | 0Ah | ||

[출처] 위키피디아
빅 엔디안 과 반대로 0x0D 가 메모리 하위 주소에 오게된다. 상위바이트로 올라가면서
차례로 나머지 값이 들어간다. 리틀 엔디안 또는 빅 엔디안에 따라 받아 들이는 쪽에서
처리를 잘못하게 되면 엉뚱한 형태가 되므로 주의가 필요하다. 예를 들어, 취약점 등을
리버싱 하는 과정에서 해당 값 들이 기록되어 있는 형태를 제대로 이해할 필요가 있다.
일단 여기서는 쉽게 요약 정리하면,
빅 엔디안값은 왼쪽-> 오른쪽 순서로 읽고, 리틀 엔디안값은 반대로 오른쪽->왼쪽 순서로
읽으면 된다는 점이다. 그리고 네트워크 상에서 표준으로 이용되는 프로토콜은
네트워크 바이트 오더인 빅 엔디안으로 생각하자.
복잡한게 싫다면 이것만 알고 있으면 된다.
참고로 다음은 리틀/빅 엔디안을 이용하는 시스템이다.
[리틀 엔디안]
- Linux on x86, x64, Alpha and Itanium
- Mac OS X on x86, x64
- OpenVMS on VAX, Alpha and Itanium
- Solaris on x86, x64, PowerPC
- Tru64 UNIX on Alpha
- Windows on x86, x64 and Itanium
[빅 엔디안]
우리가 주로 이용하는 시스템은 인텔 기반의 리눅스와 윈도우이므로 리틀 엔디안 방식이다. 단, 네트워크를 통해 전송되는 것은 빅 엔디안이다.
[참고]
1. 위키피디아
http://en.wikipedia.org/wiki/Endianness
2. Understanding Big and Little Endian Byte Order
http://betterexplained.com/articles/understanding-big-and-little-endian-byte-order/
잘봤습니다.
답글삭제고맙습니다
답글삭제